
原文地址:
https://arxiv.org/html/2308.07107v3
1介绍
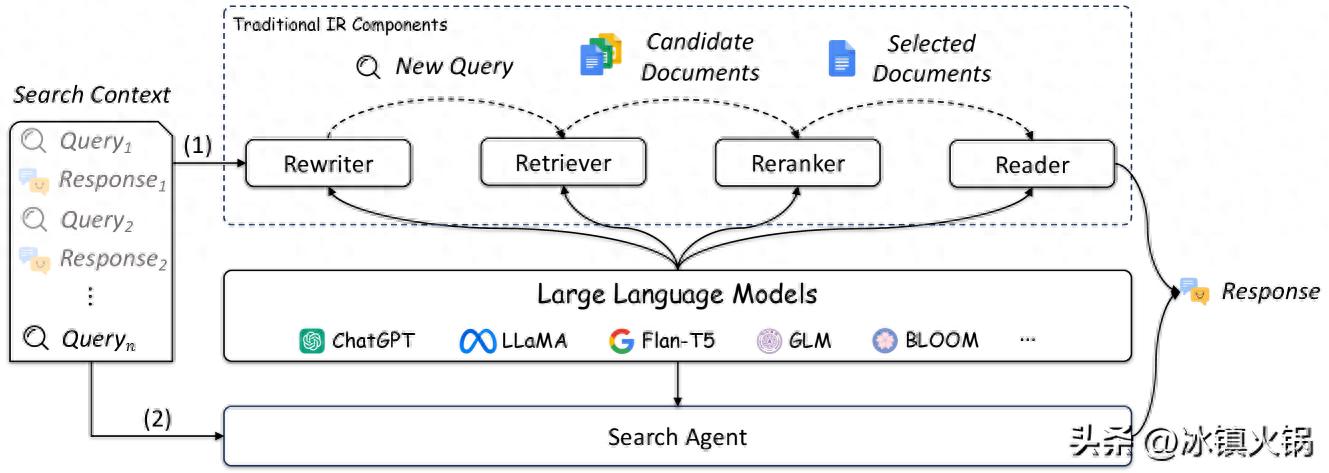 Figure 1:Overview of existing studies that apply LLMs into IR. (1) LLMs can be used to enhance traditional IR components, such as query rewriter, retriever, reranker, and reader. (2) LLMs can also be used as search agents to perform multiple IR tasks.
Figure 1:Overview of existing studies that apply LLMs into IR. (1) LLMs can be used to enhance traditional IR components, such as query rewriter, retriever, reranker, and reader. (2) LLMs can also be used as search agents to perform multiple IR tasks.信息获取是人类的基本日常需求之一。为了满足快速获取所需信息的需求,已经开发了各种信息检索(IR)系统。突出的例子包括谷歌、必应和百度等搜索引擎,它们作为互联网上的投资者关系系统,善于检索相关网页以响应用户查询,并提供方便高效的互联网信息访问。值得注意的是,IR 超出了网页检索的范围。在对话系统(聊天机器人)中,例如Microsoft小冰,Apple Siri,1 1 苹果 Siri、
https://www.apple.com/siri/ 和 Google 助理,2 2 Google 助理、
https://assistant.google.com/ IR 系统在检索对用户输入话语的适当响应方面发挥着至关重要的作用,从而产生自然流畅的人机对话。同样,在问答系统中,IR系统用于选择有效解决用户问题所必需的相关线索。在图像搜索引擎中,红外系统擅长返回与用户输入查询一致的图像。鉴于信息呈指数级增长,研究和工业界对开发有效的红外系统越来越感兴趣。
IR 系统的核心功能是检索,旨在确定用户发出的查询与要检索的内容(包括各种类型的信息,如文本、图像、音乐等)之间的相关性。在本次调查的范围内,我们只专注于审查这些文本检索系统,在这些系统中,查询文档的相关性通常通过其匹配分数来衡量3。 3 此后,“文档”一词将指任何需要检索的基于文本的内容,包括长篇文章和短篇文章。 鉴于 IR 系统在广泛的存储库上运行,检索算法的效率变得至关重要。为了改善用户体验,从上游(查询重新表述)和下游(重新排序和读取)的角度增强了检索性能。作为一种上游技术,查询重新表述旨在优化用户查询,以便它们更有效地检索相关文档。随着最近会话搜索的普及,这种技术越来越受到关注。在下游方面,开发了重新排序方法以进一步调整文档排名。与检索阶段相比,重新排序仅对检索器已检索到的有限相关文档集执行。在这种情况下,重点放在实现更高的性能而不是保持更高的效率上,从而允许在重新排名过程中应用更复杂的方法。此外,重新排名可以满足其他特定要求,例如个性化和多样化。在检索和重新排序阶段之后,加入了一个阅读组件来总结检索到的文档并向用户提供简明的文档。虽然传统的 IR 系统通常要求用户自己收集和组织相关信息;然而,读取组件是新红外系统(如新必应)的组成部分,4 4 新必应,https://www.bing.com/new 简化用户的浏览体验,节省宝贵的时间。
IR 的发展轨迹经历了一个动态的演变,从起源于基于术语的方法过渡到神经模型的整合。最初,IR以基于术语的方法和布尔逻辑为基础,专注于文档检索的关键字匹配。随着向量空间模型的引入,范式逐渐发生了变化,释放了捕捉术语之间细微语义关系的潜力。统计语言模型延续了这一进展,通过上下文和概率考虑改进了相关性估计。颇具影响力的BM25算法在这一阶段发挥了重要作用,通过考虑术语频率和文档长度的变化,彻底改变了相关性排名。IR旅程的最新篇章以神经模型的崛起为标志。这些模型擅长捕捉复杂的上下文线索和语义细微差别,重塑 IR 的格局。然而,这些神经模型仍然面临数据稀缺性、可解释性以及可能产生合理但不准确的响应等挑战。因此,IR 的发展仍然是平衡传统优势(如 BM25 算法的高效率)与现代神经架构带来的卓越能力(如语义理解)的旅程。
大型语言模型(LLM)最近已成为各个研究领域的变革力量,如自然语言处理(NLP),推荐系统,金融,甚至分子发现。这些尖端的 LLM 主要基于 Transformer 架构,并在各种文本来源(包括网页、研究文章、书籍和代码)上进行了广泛的预训练。随着其规模的不断扩大(包括模型大小和数据量),LLM 在能力方面取得了显着的进步。一方面,LLM在语言理解和生成方面表现出前所未有的熟练程度,从而产生了更像人类的反应,更符合人类的意图。另一方面,较大的LLM在处理复杂任务时表现出令人印象深刻的涌现能力,例如泛化和推理能力。值得注意的是,LLM可以有效地应用他们学到的知识和推理能力来处理新任务,只需一些特定任务的演示或适当的说明。此外,先进的技术,如情境学习,显著提高了LLM的泛化性能,而不需要对特定的下游任务进行微调。这一突破特别有价值,因为它减少了对大量微调的需求,同时实现了卓越的任务性能。在思维链等提示策略的支持下,LLM可以通过分步推理生成输出,从而驾驭复杂的决策过程。利用 LLM 令人印象深刻的功能无疑可以提高 IR 系统的性能。通过整合这些复杂的语言模型,IR系统可以为用户提供更准确的响应,最终重塑信息访问和检索的格局。
在开发新型IR系统方面,已经做出了初步的努力,以利用LLM的潜力。值得注意的是,在实际应用方面,New Bing 旨在通过从不同的网页中提取信息并将其压缩成简洁的摘要来改善用户使用搜索引擎的体验,作为对用户生成查询的响应。在研究界,LLMs已被证明在IR系统的特定模块(如检索器)中很有用,从而提高了这些系统的整体性能。由于 LLM 增强型 IR 系统的快速发展,因此必须全面回顾其最新进展和挑战。
我们的调查对 LLM 和 IR 系统之间的交叉点进行了深入的探索,涵盖了查询重写器、检索器、重排序器和读取器等关键视角(如图 1 所示)5。 5 到目前为止,还没有 LLM 的正式定义。在本文中,我们主要关注参数超过1B的模型。我们还注意到,有些方法并不依赖于这种严格定义的 LLM,但由于它们的代表性,我们仍然在本调查中对它们进行了介绍。 我们还包括一些最近的研究,这些研究利用 LLM 作为搜索代理来执行各种 IR 任务。该分析增强了我们对 LLM 在推进 IR 领域的潜力和局限性的理解。在本次调查中,我们通过收集有关 LLM4IR 的相关论文和资源来创建一个 Github 存储库6 6
https://github.com/RUC-NLPIR/LLM4IR-Survey 我们将继续用更新的论文更新存储库。本次调查也将根据该地区的发展情况定期更新。我们注意到,有几项针对PLM、LLM及其应用(例如AIGC或推荐系统)的调查。其中,我们强烈推荐LLMs的调查,它为LLMs的许多重要方面提供了系统而全面的参考。此外,我们注意到一篇观点论文讨论了在满足LLM时IR的机会。这将是对这项关于未来方向的调查的极好补充。
本调查的其余部分组织如下: 第 2 节介绍了 IR 和 LLM 的背景。 第 3、4、5、VII 节分别从查询重写器、检索器、重新排序器和读取器四个角度回顾了最近的进展,这是 IR 系统的四个关键组成部分。然后,第8节讨论了未来研究的一些潜在方向。最后,我们总结了主要发现,结束了第9节的调查。
2背景
2.1信息检索
信息检索 (IR) 作为计算机科学的一个重要分支,旨在从大型存储库中有效地检索与用户查询相关的信息。通常,用户通过以文本形式提交查询来与系统交互。随后,IR 系统承担将这些用户提供的查询与索引数据库进行匹配和排序的任务,从而便于检索最相关的结果。
随着时间的推移,随着各种模型的出现,IR领域取得了重大进展。布尔模型就是这样一种早期模型,它使用布尔逻辑运算符来组合查询词并检索满足特定条件的文档。基于“词袋”假设,向量空间模型在基于术语的空间中将文档和查询表示为向量。然后,通过评估查询和文档向量之间的词汇相似性来执行相关性估计。通过使用倒挂索引对文本内容进行有效组织,该模型的效率得到了进一步提高。为了采用更复杂的方法,人们引入了统计语言模型来估计术语出现的可能性并整合上下文信息,从而实现更准确和上下文感知的检索。近年来,神经IR 范式在研究界引起了相当大的关注。通过利用神经网络强大的表示能力,该范式可以捕获查询和文档之间的语义关系,从而显著提高检索性能。
研究人员已经确定了几个对 IR 系统的性能和有效性产生影响的挑战,例如查询模糊性和检索效率。鉴于这些挑战,研究人员将注意力转向检索过程中的关键模块,旨在解决特定问题并实现相应的改进。这些模块在改善红外管道和提升系统性能方面的关键作用怎么强调都不为过。在本次调查中,我们重点关注以下四个模块,这些模块已被 LLM 大大增强。
Query Rewriter 是一个必不可少的 IR 模块,旨在提高用户查询的精度和表现力。该模块位于 IR 管道的早期阶段,承担着完善或修改初始查询以更准确地满足用户信息要求的关键作用。作为查询重写的一个组成部分,查询扩展技术(伪相关性反馈就是一个突出的例子)代表了实现查询表达式细化的主流方法。除了在提高一般方案的搜索效率方面具有实用性外,查询重写器还可以在各种专用检索上下文(如个性化搜索和对话搜索)中找到应用,从而进一步证明其重要性。
如本文所述,Retriever 通常用于 IR 的早期阶段用于文档调用。检索技术的发展反映了对更有效和高效方法的不断追求,以应对不断增长的文本馆藏带来的挑战。多年来,在红外系统的大量实验中,经典的“词袋”模型BM25证明了其强大的性能和高效率。随着神经 IR 范式的兴起,流行的方法主要围绕着将查询和文档投射到高维向量空间中,然后通过内积计算计算它们的相关性分数。这种范式转变可以更有效地理解查询-文档关系,利用向量表示的强大功能来捕获语义相似性。
Reranker 作为检索管道中的另一个关键模块,主要侧重于对检索到的文档集中的文档进行细粒度的重新排序。与强调效率和有效性平衡的检索器不同,reranker 模块更强调文档排名的质量。为了提高搜索结果的质量,研究人员深入研究了比传统向量内积更复杂的匹配方法,从而为重新排名者提供更丰富的匹配信号。此外,reranker有助于采用专门的排名策略,以满足不同的用户需求,例如个性化和多样化的搜索结果。通过集成特定领域的目标,reranker 模块可以提供量身定制且有目的的搜索结果,从而增强整体用户体验。
随着LLM技术的快速发展,Reader已经发展成为一个关键的模块。它能够理解实时用户意图并根据检索到的文本生成动态响应,这彻底改变了 IR 结果的呈现方式。与呈现候选文档列表相比,阅读器模块更直观地组织答案文本,模拟人类获取信息的自然方式。为了提高生成的回复的可信度,将参考文献整合到生成的回复中是读者模块的一种有效技术。
此外,研究人员还探索统一上述模块,以开发一种称为搜索代理的新型 LLM 驱动的搜索模型。搜索代理的特点是模拟自动搜索和结果理解过程,为用户提供准确且易于理解的答案。WebGPT 是该类别的开创性工作,它将搜索过程建模为搜索引擎环境中基于 LLM 的代理的一系列操作,自主完成整个搜索管道。通过集成现有的搜索堆栈,搜索代理有可能成为未来 IR 的新范式。
2.2大型语言模型
语言模型 (LM) 旨在通过考虑来自前一个单词的上下文信息来计算单词序列的生成可能性,从而预测后续单词的概率。因此,通过采用某些单词选择策略(例如贪婪解码或随机抽样),LM可以熟练地生成自然语言文本。尽管LM的主要目标在于文本生成,但最近的研究表明,可以有效地将各种自然语言处理问题重新表述为文本到文本的格式,从而使它们易于通过文本生成来解决。这导致LM成为大多数与文本相关的问题的实际解决方案。
LMs的进化可分为四个主要阶段,如先前文献所述。最初,LM植根于统计学习技术,被称为统计语言模型。这些模型通过采用马尔可夫假设来根据前面的单词预测后续单词,从而解决了单词预测的问题。此后,引入了神经网络,特别是递归神经网络(RNN)来计算文本序列的可能性并建立神经语言模型。这些进步使得利用 LM 进行表示学习成为可能,而不仅仅是词序建模。ELMo首先提出,通过在大规模语料库上预训练双向LSTM(biLSTM)网络来学习上下文化的词表示,然后对特定的下游任务进行微调。类似地,BERT 建议在大型语料库上使用专门设计的掩码语言建模 (MLM) 任务和下一句预测 (NSP) 任务来预训练 Transformer 编码器。这些研究开创了预训练语言模型(PLM)的新时代,“预训练后微调”范式成为流行的学习方法。沿着这条思路,已经开发了许多生成式 PLM(例如 GPT-2 、BART 和 T5 )来解决文本生成问题,包括摘要、机器翻译和对话生成。最近,研究人员观察到,增加PLM的规模(例如,模型大小或数据量)可以持续提高其在下游任务中的性能(这种现象通常被称为扩展定律)。此外,大型PLM在处理复杂任务方面表现出有前途的能力(称为紧急能力),这在小型PLM中并不明显。因此,研究界将这些大型 PLM 称为大型语言模型 (LLM)。
 Figure 2:The evolution of LLMs (encoder-decoder and decoder-only structures).
Figure 2:The evolution of LLMs (encoder-decoder and decoder-only structures).如图 2 所示,现有的 LLM 可以根据其体系结构分为两组:编码器-解码器 和仅解码器 模型。编码器-解码器模型包含一个编码器组件,用于将输入文本转换为向量,然后用于生成输出文本。例如,T5 是一个编码器-解码器模型,它将每个自然语言处理问题转换为文本到文本的形式,并将其作为文本生成问题解决。相比之下,以 GPT 为代表的纯解码器模型依赖于 Transformer 解码器架构。它使用带有对角线注意力掩码的自注意力机制从左到右生成一系列单词。GPT-3 是第一个包含超过 100B 参数的模型,在它的成功基础上,几个值得注意的模型受到了启发,包括 GPT-J、BLOOM 、OPT 、Chinchilla 和 LLaMA 。这些模型遵循与 GPT-3 类似的 Transformer 解码器结构,并在各种数据集组合上进行训练。
由于 LLM 的参数数量众多,因此针对特定任务(如 IR)进行微调通常被认为是不切实际的。因此,已经建立了两种应用LLM的流行方法:上下文学习(ICL)和参数高效微调。ICL是LLM的紧急能力之一,使他们能够根据提供的输入上下文来理解和提供答案,而不仅仅是依靠他们的训练前知识。这种方法只需要用自然语言制定任务描述和演示,然后将它们作为输入提供给 LLM。值得注意的是,ICL 不需要参数调整。此外,通过采用思维链提示,可以进一步增强ICL的功效,包括多个演示(描述思维链示例)来指导模型的推理过程。ICL 是将 LLM 应用于 IR 的最常用方法。参数高效微调旨在减少可训练参数的数量,同时保持令人满意的性能。例如,LoRA 已被广泛应用于开源 LLM(例如 LLaMA 和 BLOOM)。最近,QLoRA 被提出通过利用冻结的 4 位量化 LLM 进行梯度计算来进一步减少内存使用。尽管探索了针对各种NLP任务的参数效率微调,但其在IR任务中的实现仍然相对有限,代表了未来研究的潜在途径。
 Figure 3:An example of LLM-based query rewriting for ad-hoc search. The example is cited from the Query2Doc paper . LLMs are used to generate a passage to supplement the original query, where =0 and >0 correspond to zero-shot and few-shot scenarios.
Figure 3:An example of LLM-based query rewriting for ad-hoc search. The example is cited from the Query2Doc paper . LLMs are used to generate a passage to supplement the original query, where =0 and >0 correspond to zero-shot and few-shot scenarios.3查询重写器
现代 IR 系统中的查询重写对于提高搜索查询的有效性和准确性至关重要。它改革了用户的原始查询,以更好地匹配搜索结果,从而缓解了查询和目标文档之间的模糊查询或词汇不匹配等问题。此任务不仅仅是同义词替换,还需要了解用户意图和查询上下文,尤其是在对话查询等复杂搜索中。有效的查询重写可以提高搜索引擎的性能。
传统的查询重写方法通过使用排名靠前的相关文档中的信息扩展初始查询来提高检索性能。主要使用的方法包括相关性反馈,基于词嵌入的方法等。然而,语义理解和理解用户搜索意图的能力有限,限制了它们在捕获用户意图的全部范围方面的表现。
LLM 的最新进展为增强查询重写能力提供了有希望的机会。一方面,考虑到查询的上下文和微妙之处,LLM 可以提供更准确且与上下文相关的重写。另一方面,LLM可以利用其广泛的知识来生成同义词和相关概念,增强查询以涵盖更广泛的相关文档,从而有效地解决词汇不匹配问题。在以下各节中,我们将介绍最近在查询重写中使用 LLM 的工作。
 Figure 4:An example of LLM-based query rewriting for conversational search. The example is cited from LLMCS . The LLM is used to generate a query based on the demonstrations and previous search context. Additional responses are required to be generated for improving the query understanding. =0 and >0 correspond to zero-shot and few-shot scenarios.
Figure 4:An example of LLM-based query rewriting for conversational search. The example is cited from LLMCS . The LLM is used to generate a query based on the demonstrations and previous search context. Additional responses are required to be generated for improving the query understanding. =0 and >0 correspond to zero-shot and few-shot scenarios.3.1重写方案
查询重写通常提供两种方案:临时检索(主要解决查询与候选文档之间的词汇不匹配)和对话搜索(根据不断发展的对话优化查询)。接下来的章节将深入探讨查询重写在这两个领域中的作用,并探讨 LLM 如何增强这一过程。
3.1.1临时检索
在临时检索中,查询通常简短且不明确。在这种情况下,查询重写的主要目标包括添加同义词或相关术语以解决词汇不匹配问题,并澄清不明确的查询以更准确地与用户意图保持一致。从这个角度来看,LLM 在查询重写方面具有先天优势。首先,LLM 对语言语义有深刻的理解,使他们能够更有效地捕获查询的含义。此外,LLM 可以利用他们对不同数据集的广泛训练来生成上下文相关的同义词并扩展查询,从而确保更广泛、更精确的搜索结果覆盖。此外,研究表明,LLMs对外部事实语料库和深思熟虑的模型设计的整合进一步提高了它们生成有效查询重写的准确性,特别是对于特定任务。
目前,有许多研究利用 LLM 在临时检索中重写查询。我们以典型的 Query2Doc 方法 为例。如图 3 所示,Query2Doc 提示 LLM 根据原始查询生成相关段落(“口袋妖怪绿色是什么时候发布的?随后,通过合并生成的段落来扩展原始查询。检索器模块使用此新查询来检索相关文档的列表。值得注意的是,生成的段落包含额外的详细信息,例如“Pokemon Green 于 2 月 27 日在日本发布”,这在一定程度上有效地缓解了“词汇不匹配”的问题。
除了解决“词汇不匹配”问题之外,其他工作还利用LLMs来应对临时检索中的不同挑战。例如,PromptCase 在法律案例检索中利用 LLM 将复杂的查询简化为更可搜索的形式。这涉及使用 LLM 来识别法律事实和问题,然后使用基于提示的编码方案进行有效的语言模型编码。
3.1.2对话搜索
对话式搜索中的查询重写在增强搜索体验方面起着关键作用。与临时检索中的传统查询不同,对话搜索涉及类似对话的交互,其中上下文和用户意图随着每次交互而变化。在对话搜索中,查询重写涉及了解整个对话的上下文、澄清任何歧义以及根据用户历史记录个性化响应。该过程包括基于对话信息的动态查询扩展和优化。这使得对话式查询重写成为一项复杂的任务,它超越了传统搜索,专注于自然语言理解和以用户为中心的交互。
在 LLM 时代,在会话搜索任务中利用 LLM 有几个优势。首先,LLM具有较强的上下文理解能力,能够在用户与系统多轮对话的上下文中更好地理解用户的搜索意图。其次,LLM表现出强大的生成能力,使它们能够模拟用户与系统之间的对话,从而促进更强大的搜索意图建模。
LLMCS框架是一种开创性的方法,它利用LLMs在会话上下文中有效地提取和理解用户搜索意图。正如他们的工作所说明的那样,LLMCS 使用 LLM 从各个角度生成查询重写和广泛的假设系统响应。这些输出被组合成一个全面的表示形式,有效地捕捉了用户的完整搜索意图。实验结果表明,通过简洁的查询重写,包含详细的假设响应,通过添加更合理的搜索意图,可以显著提高搜索性能。Ye et al. 声称,人工查询重写可能缺乏足够的信息来获得最佳检索性能。它为格式正确的 LLM 生成的查询重写定义了四个基本属性。结果表明,与人工重写相比,他们的方法信息查询重写可以显著提高检索性能。
此外,LLM 可以用作会话密集检索中的数据扩展工具。由于制作手写对话的成本很高,数据稀缺性在对话搜索领域带来了重大挑战。为了解决这个问题,CONVERSER 使用LLMs通过小镜头演示生成合成的段落-对话对。此外,它使用六个域内对话的最小数据集有效地训练密集的检索器,从而缓解了数据稀疏性的问题。
3.2重写知识
查询重写通常需要额外的语料库来优化初始查询。考虑到 LLM 在其参数中包含了世界知识,它们自然能够重写查询。我们将这些完全依赖于 LLM 的内在知识的方法称为仅 LLM 方法。虽然法学硕士包含广泛的知识,但它们在专业领域可能还不够。此外,LLM 可能会引入概念漂移,从而导致嘈杂的相关性信号。为了解决此问题,一些方法合并了特定于域的语料库,以在查询重写中提供更详细和相关的信息。我们将通过特定领域语料库增强以提高 LLM 性能的方法称为基于语料库增强的 LLM 方法。在本节中,我们将详细介绍这两种方法。
3.2.1仅限 LLM 的方法
LLM 能够将知识存储在其参数中,因此利用这些知识进行查询重写是很自然的选择。作为基于LLM的查询重写的开创性工作,HyDE根据给定的查询由LLM生成一个假设的文档,然后使用密集检索器从语料库中检索与生成的文档相关的文档。Query2doc 通过提示 LLM 和少量演示来生成伪文档,然后使用生成的伪文档扩展查询。此外,还研究了不同提示方法和不同模型大小对查询重写的影响。为了更好地适应冻结的检索器和基于LLM的读者,采用了一种小型语言模型作为重写器,该模型使用强化学习技术进行训练,并由基于LLM的阅读器提供奖励。GFF 提出了一种用于查询扩展的“生成、过滤和融合”方法。它使用 LLM 通过推理链创建一组相关关键字。然后,使用自一致性筛选器来识别最重要的关键字,这些关键字与下游重新排名任务的原始查询连接起来。
值得注意的是,尽管这些方法的设计不同,但它们都依赖于存储在LLM中的世界知识,而没有额外的语料库。
3.2.2基于语料库增强的LLM方法
尽管 LLM 表现出非凡的能力,但缺乏特定领域的知识可能会导致产生幻觉或不相关的查询。为了解决这个问题,最近的研究提出了一种混合方法,该方法使用外部文档语料库增强了基于LLM的查询重写方法。
为什么要合并文档语料库?文档语料库的集成提供了几个显着的优点。首先,它通过使用相关文档来优化查询生成、减少不相关的内容并改进上下文适当的输出,从而提高相关性。其次,用特定领域的最新信息和专业知识来增强 LLM,使他们能够有效地处理当前和特定于某些领域的查询。
如何合并文档语料库?由于 LLM 的灵活性,已经提出了各种范式将文档语料库合并到基于 LLM 的查询重写中,可以总结如下。
∙ 基于 LLM 的重写和伪相关性反馈 (PRF) 检索结果的后期融合。传统的PRF方法利用从文档语料库中检索到的相关文档来重写查询,从而将查询限制为目标语料库中包含的信息。相反,基于 LLM 的重写方法提供了语料库中不存在的外部上下文,这更加多样化。这两种方法都有可能独立地提高检索性能。因此,将它们组合在一起的一种简单策略是使用加权融合方法进行检索结果。
∙ 在 LLM 的提示中合并检索到的相关文档。在 LLM 时代,在提示中加入指令是实现特定功能的最灵活方法。QUILL 和 CAR 说明了查询的检索增强如何为 LLM 提供显著增强查询理解的上下文。LameR 通过使用 LLM 扩展来改进简单的 BM25 检索器,引入了 retrieve-rewrite-retrieve 框架,从而进一步实现了这一点。实验结果表明,即使是基本的基于术语的检索器,在与基于 LLM 的重写器配对时,也可以达到相当的性能。此外,InteR 提出了一个搜索引擎和LLM之间的多轮交互框架。这使搜索引擎能够使用 LLM 生成的见解扩展查询,而 LLM 则使用来自搜索引擎的相关文档来优化提示。
∙ 通过伪相关性反馈 (PRF) 增强生成相关性反馈 (GRF) 的事实性。尽管生成文档通常具有相关性和多样性,但它们表现出幻觉特征。相比之下,传统文件通常被视为事实信息的可靠来源。受这一观察结果的启发,GRM提出了一种称为相关性感知样本估计(RASE)的新技术。RASE 利用从集合中检索到的相关文档为生成的文档分配权重。通过这种方式,GRM确保相关性反馈不仅多样化,而且保持高度的真实性。
3.3重写方法
在查询重写中利用 LLM 主要有三种方法:提示方法、微调和知识蒸馏。提示方法涉及使用特定的提示来指导 LLM 输出,从而提供灵活性和可解释性。微调在特定数据集或任务上调整预先训练的 LLM,以提高特定领域的性能,从而减轻 LLM 世界知识的一般性质。另一方面,知识蒸馏将 LLM 知识转移到轻量级模型中,从而简化了与检索增强相关的复杂性。在下一节中,我们将详细介绍这三种方法。
3.3.1提示
TABLE I:Partial Examples of different prompting methods in query rewriting.
Methods | Prompts |
Zero-shot | |
HyDE | Please write a passage to answer the question. Question: {#Question} Passage: |
LameR | Give a question {#Question} and its possible answering passages: A. {#Passage 1} B. {#Passage 2} C. {#Passage 3} … Please write a correct answering passage. |
Few-shot | |
Query2Doc | Write a passage that answers the given query: |
Query: {#Query 1} | |
Passage: {#Passage 1} | |
… | |
Query: {#Query} | |
Passage: | |
Chain-of-Thought | |
CoT | Answer the following query based on the context: |
Context: {#PRF doc 1} {#PRF doc 2} {#PRF doc 3} | |
Query: {#Query} | |
Give the rationale before answering | |
LLM 中的提示是指提供特定指令或上下文来指导模型生成文本的技术。提示用作条件反射信号,并影响模型的语言生成过程。现有的提示策略大致可分为三类:零样本提示、少提示和思维链(CoT)提示。
∙ 零镜头提示。零样本提示涉及指示模型生成有关特定主题的文本,而无需事先接触该领域或主题中的训练示例。该模型依靠其预先存在的知识和语言理解,为原始查询生成连贯且上下文相关的扩展术语。实验表明,零样本提示是一种简单而有效的查询重写方法。
∙ 少量提示。小样本提示,也称为上下文学习,涉及为模型提供一组与所需任务或领域相关的有限示例或演示。这些示例作为一种显式指令形式,允许模型根据手头的特定任务或领域调整其语言生成。Query2Doc 提示 LLM 编写一个文档,该文档使用排名数据集提供的一些演示查询-文档对(例如 MSMARCO 和 NQ 探索了八种不同的提示,例如提示LLM生成查询扩展词而不是整个伪文档和CoT提示。表一中有一些说明性提示。这项工作比 Query2Doc 进行了更多的实验,但结果表明,建议的提示不如 Query2Doc 有效。
∙ 思维链提示。CoT提示是一种涉及迭代提示的策略,其中模型被提供一系列指令或部分输出。在会话式搜索中,查询重写的过程是多回合的,这意味着查询应该随着搜索引擎和用户之间的交互而逐步完善。这个过程自然与CoT过程相吻合。如图 4 所示,用户可以通过在每个回合中添加一些指令来执行 CoT 过程,例如“基于之前的所有回合,xxx”。在临时搜索中,查询重写只有一轮,因此只能以简单粗暴的方式完成 CoT。例如,如表I所示,研究人员在说明中添加了“在之前给出理由”,以提示LLM进行深入思考。
3.3.2微调
微调是使 LLM 适应特定领域的有效方法。此过程通常从预训练的语言模型(如 GPT-3)开始,然后在为目标域量身定制的数据集上进一步训练。这种特定于领域的培训使 LLM 能够学习与该领域相关的独特模式、术语和上下文,从而能够提高其生成高质量查询重写的能力。
BEQUE 利用 LLM 重写电子商务产品搜索中的查询。它设计了三个监督微调 (SFT) 任务:电子商务查询重写的质量分类、产品标题预测和 CoT 查询重写。据我们所知,它是第一个直接微调 LLM 的模型,包括 ChatGLM 、ChatGLM2.0 、Baichuan 和 Qwen ,专门用于查询重写任务。在SFT阶段之后,BEQUE使用离线系统来收集有关重写的反馈,并通过对象对齐阶段进一步使重写器与电子商务搜索目标保持一致。在线 A/B 测试证明了该方法的有效性。
3.3.3知识蒸馏
尽管基于 LLM 的方法在查询重写任务方面表现出显著的改进,但由于 LLM 的计算需求导致的大量延迟,它们在在线部署中的实际实现受到阻碍。为了应对这一挑战,知识蒸馏已成为该行业的一项重要技术。在QUILL 框架中,提出了一种两阶段蒸馏方法。这种方法需要使用检索增强的 LLM 作为教授模型,使用普通 LLM 作为教师模型,使用轻量级 BERT 模型作为学生模型。教授模型在两个广泛的数据集上进行训练,即 Orcas-I 和 EComm ,这些数据集是专门为理解查询意图而策划的。随后,采用两阶段蒸馏过程将知识从教授模型转移到教师模型,然后从教师模型向学生模型转移知识。实证结果表明,这种知识蒸馏方法超越了从基础到 XXL 的模型大小的简单放大,从而产生了更实质性的改进。在最近提出的“重写-检索-读取”框架中,首先使用LLM通过提示重写查询,然后使用检索增强读取过程。为了提高框架的有效性,我们合并了一个可训练的重写器,作为一个小型语言模型实现,以进一步调整搜索查询,以符合冻结检索器和 LLM 读者的要求。重写器的改进涉及两步训练过程。最初,监督热身训练是使用伪数据进行的。然后,将先检索后读取的管道描述为强化学习方案,重写器的训练充当策略模型,以最大化管道性能奖励。
TABLE II:Summary of existing LLM-enhanced query rewriting methods. “Docs” and “KD” stand for document corpus and knowledge distillation, respectively.
方法 | 目标 | Data | Generation |
HyDE | Ad-hoc | LLMs | 促使 |
Jagerman et al. | Ad-hoc | LLMs | 促使 |
查询2文档 | Ad-hoc | LLMs | 促使 |
Ma et al. | Ad-hoc | LLMs | 微调 |
提示案例 | Ad-hoc | LLMs | 促使 |
GRF+PRF | Ad-hoc | LLM + 文档 | 促使 |
GRM | Ad-hoc | LLM + 文档 | 促使 |
InteR | Ad-hoc | LLM + 文档 | 促使 |
LameR | Ad-hoc | LLM + 文档 | 促使 |
汽车 | Ad-hoc | LLM + 文档 | 促使 |
羽毛笔 | Ad-hoc | LLM + 文档 | KD & 微调 |
LLMCS | 对话的 | LLMs | 促使 |
对话者 | 对话的 | LLMs | 促使 |
Ye等人 | 对话的 | LLMs | 促使 |
3.4局限性
虽然 LLM 为查询重写提供了很有前途的功能,但它们也遇到了一些挑战。在这里,我们概述了基于 LLM 的查询重写器的两个主要限制。
3.4.1概念漂移
当使用 LLM 进行查询重写时,它们可能会引入不相关的信息,称为概念漂移,因为它们具有广泛的知识库和产生详细和冗余内容的倾向。虽然这可以丰富查询,但也存在生成不相关或偏离目标结果的风险。
一些研究报道了这种现象,这些研究强调了在基于LLM的查询重写中需要一种平衡的方法,确保保持原始查询的本质和重点,同时利用LLM的能力来增强和澄清查询。这种平衡对于有效的搜索和红外应用至关重要。
3.4.2检索性能与扩展效应的相关性
最近,一项综合研究对各种扩张技术和下游排名模型进行了实验,结果显示,猎犬的性能与扩张的好处之间存在显著的负相关关系。具体来说,虽然扩张往往会提高较弱模型的分数,但它通常会伤害较强的模型。这一观察结果提出了一种战略方法:使用较弱的模型进行扩展,或者在目标数据集的格式与训练语料库有很大差异的情况下使用扩展。在其他情况下,建议避免扩展以保持相关性信号的清晰度。
4检索器
在 IR 系统中,检索器充当首过文档过滤器,以收集广泛相关的文档以供用户查询。鉴于 IR 系统中有大量文档,检索器查找相关文档的效率对于保持搜索引擎性能至关重要。同时,高召回率对检索器也很重要,因为检索到的文档随后被输入排名器,为用户生成最终结果,这决定了搜索引擎的排名质量。
近年来,检索模型已经从依赖统计算法转向依赖神经模型。后一种方法表现出卓越的语义能力,擅长理解复杂的用户意图。神经猎犬的成功取决于两个关键因素:数据和模型。从数据角度来看,大量高质量的训练数据是必不可少的。这使猎犬能够获得全面的知识和准确的匹配模式。此外,检索数据(即发出的查询和文档语料库)的内在质量会显著影响检索性能。从模型的角度来看,强表征神经架构允许检索器有效地存储和应用从训练数据中获得的知识。
不幸的是,有一些长期挑战阻碍了检索模型的发展。首先,用户查询通常简短且模棱两可,因此很难准确理解用户对检索器的搜索意图。其次,文档通常包含冗长的内容和大量的噪声,这给对长文档进行编码和提取检索模型的相关信息带来了挑战。此外,人工注释的相关性标签的收集既费时又费钱。它限制了检索器的知识边界及其跨不同应用程序域泛化的能力。此外,主要基于BERT构建的现有模型架构表现出固有的局限性,从而限制了检索器的性能潜力。最近,LLM在语言理解、文本生成和推理方面表现出非凡的能力。这促使研究人员利用这些能力来应对上述挑战,并帮助开发卓越的检索模型。粗略地说,这些研究可以分为两组,即(1)利用LLM生成搜索数据,以及(2)利用LLM来增强模型架构。
4.1利用 LLM 生成搜索数据
鉴于搜索数据的质量和数量,关于如何通过 LLM 提高检索性能,有两种普遍的观点。第一种观点围绕搜索数据细化方法展开,该方法侧重于重新表述输入查询以精确呈现用户意图。第二种观点涉及训练数据增强方法,该方法利用 LLM 的生成能力来放大密集检索模型的训练数据,尤其是在零样本或少样本场景中。
4.1.1搜索数据细化
通常,输入查询由短句或基于关键字的短语组成,这些短语可能不明确,并且包含多个可能的用户意图。在这种情况下,准确确定特定的用户意图至关重要。此外,文档通常包含冗余或嘈杂的信息,这给检索器提取查询和文档之间的相关性信号带来了挑战。利用 LLM 强大的文本理解和生成能力为这些挑战提供了一个有前途的解决方案。到目前为止,该领域的研究工作主要集中在使用 LLM 作为查询重写器,旨在优化输入查询,以便更精确地表达用户的搜索意图。第3节对这些研究进行了全面的概述,因此本节不再进一步阐述。除了查询重写之外,一个有趣的探索途径涉及使用 LLM 通过优化冗长的文档来提高检索的有效性。这个有趣的领域仍然有待进一步的调查和推进。
 Figure 5:Two typical frameworks for LLM-based data augmentation in the retrieval task (right), along with their prompt examples (left). Note that the methods of relevance label generation do not treat questions as inputs but regard their generation probabilities conditioned on the retrieved passages as soft relevance labels.
Figure 5:Two typical frameworks for LLM-based data augmentation in the retrieval task (right), along with their prompt examples (left). Note that the methods of relevance label generation do not treat questions as inputs but regard their generation probabilities conditioned on the retrieved passages as soft relevance labels.TABLE III:The comparison of existing data augmentation methods powered by LLMs for training retrieval models.方法# 示例Generator合成数据过滤方式LLM的调优一对 3Curie相关查询生成概率固定Ma et al. 0-2Alpaca-LLaMA & tk-Instruct相关查询-固定InPairs-v2 3GPT-J相关查询相关性得分来自微调单T5-3B固定提示器 0-8FLAN相关查询往返筛选固定TQGen 0T0相关查询生成概率固定UDAPDR 0-3GPT3 和 FLAN-T5-XXL相关查询往返筛选固定SPTAR 1-2LLaMA-7B & Vicuna-7B相关查询BM25 滤波软提示调整ART 0T5-XL & T5-XXL软相关性标签-固定
4.1.2训练数据增强
由于人工注释标签的经济成本和时间成本高昂,训练神经检索模型的一个常见问题是缺乏训练数据。幸运的是,LLM在文本生成方面的出色能力提供了一个潜在的解决方案。一个关键的研究重点在于设计策略,利用LLM的能力来生成伪相关信号,并增强检索任务的训练数据集。
为什么我们需要数据增强?以前对神经检索模型的研究集中在监督学习上,即使用来自特定领域的标记数据训练检索模型。例如,MS MARCO 提供了一个庞大的存储库,其中包含100万个段落、200,000多个文档和100,000个带有人工注释相关性标签的查询,这极大地促进了监督检索模型的开发。但是,这种范式本质上限制了检索器对来自其他域的分布外数据的泛化能力。检索模型的应用范围从自然问答到生物医学 IR 不等,并且为来自不同领域的数据注释相关性标签的成本很高。因此,人们开始需要零样本和少样本学习模型来解决这个问题。在没有足够标签信号的情况下,提高模型在目标域中的有效性的一种常见做法是通过数据增强。
如何应用 LLM 进行数据增强?在IR的场景中,很容易收集大量文件。然而,具有挑战性和成本高昂的任务在于收集真实的用户查询并相应地标记相关文档。考虑到LLM强大的文本生成能力,许多研究人员建议使用LLM驱动的过程来创建基于现有集合的伪查询或相关性标签。这些方法有助于构建相关的查询-文档对,从而扩大检索模型的训练数据。根据生成数据的类型,有两种主流方法可以补充基于LLM的数据增强检索模型,即伪查询生成和相关性标签生成。他们的框架如图 5 所示。接下来,我们将对相关研究进行概述。
∙ 伪查询生成。鉴于文档的丰富性,一个简单的想法是使用 LLM 来生成相应的伪查询。inPairs 提供了一个这样的例子,它利用了 GPT-3 的上下文学习能力。此方法使用查询文档对的集合作为演示。这些对与文档组合并作为 GPT-3 的输入呈现,GPT-3 随后为给定文档生成可能的相关查询。通过将相同的演示与各种文档相结合,可以轻松创建大量合成训练样本,并支持在特定目标域上对检索器进行微调。最近的研究也利用开源的LLM,如Alpaca-LLaMA和tk-Instruct,来产生足够的伪查询和应用课程学习来预训练密集的检索器。为了提高这些合成样本的可靠性,采用了微调模型(例如,在MSMARCO 上微调的monoT5-3B模型)来过滤生成的查询。只有估计相关性分数最高的顶级对才会被保留用于训练。这种“生成然后过滤”范式可以以往返过滤方式迭代进行,即首先在生成的样本上微调检索器,然后使用此检索器过滤生成的样本。重复这些类似EM的步骤,直到收敛可以产生高质量的训练集。此外,通过调整给 LLM 的提示,它们可以生成不同类型的查询。这种能力允许对具有各种模式的真实查询进行更准确的模拟。
在实践中,通过 LLM 生成大量伪查询的成本很高,如何平衡生成成本和生成样本的质量已成为一个紧迫的问题。为了解决这个问题,提出了UDAPDR ,它首先使用目标域的LLM生成一组有限的综合查询。这些高质量的示例随后被用作较小模型的提示,以生成大量查询,从而为该特定域构建训练集。值得注意的是,上述研究主要依赖于具有冻结参数的固定LLM。根据经验,优化 LLM 的参数可以显著提高它们在下游任务中的性能。不幸的是,这种追求受到对计算资源的高需求的阻碍。为了克服这一障碍,SPTAR 引入了一种软提示调整技术,该技术仅在训练过程中优化提示的嵌入层。这种方法使 LLM 能够更好地适应生成伪查询的任务,从而在训练成本和生成质量之间取得有利的平衡。
除了上述研究之外,伪查询生成方法还被引入其他应用场景,如会话密集检索和多语言密集检索。
∙ 相关性标签生成。在一些检索的下游任务中,例如问答,收集问题也就足够了。然而,将这些问题与支持证据段落联系起来的相关性标签非常有限。在这种情况下,利用 LLM 生成相关性标签的能力是一种很有前途的方法,可以增强检索器的训练语料库。最近的一种方法,ART,就是这种方法的例证。它首先检索每个问题的热门相关段落。然后,它使用 LLM 来生成以这些顶部段落为条件的问题的生成概率。在归一化过程之后,这些概率将用作检索器训练的软相关性标签。
此外,为了突出相应方法之间的异同,我们在表III中给出了一个比较结果。它从各个角度比较了上述方法,包括示例数量、使用的生成器、生成的合成数据类型、用于过滤合成数据的方法以及 LLM 是否经过微调。此表有助于更清楚地了解这些方法的情况。
4.2使用 LLM 来增强模型架构
利用LLM出色的文本编码和解码能力,与早期的小型模型相比,可以更精确地理解查询和文档。研究人员一直在努力利用LLM作为构建高级检索模型的基础。这些方法可以分为两类,即密集检索器和生成检索器。
4.2.1密集检索器
除了数据的数量和质量外,模型的代表性能力也极大地影响了检索器的功效。受到LLM编码和理解自然语言的出色能力的启发,一些研究人员利用LLM作为检索编码器,并研究了模型规模对检索器性能的影响。
一般检索器。由于检索器的有效性主要依赖于文本嵌入的能力,因此文本嵌入模型的演进往往对检索器的开发进度产生重大影响。在LLM时代,OpenAI做出了开创性的工作。他们将相邻的文本段视为正对,以促进一组文本嵌入模型的无监督预训练,这些模型表示为 cpt-text,其参数值从 300M 到 175B 不等。在MS MARCO 和BEIR 数据集上进行的实验表明,更大的模型尺度有可能提高文本搜索任务的无监督学习和迁移学习的性能。然而,对于大多数研究人员来说,从头开始预训练 LLM 的成本高得令人望而却步。为了克服这一局限性,一些研究使用预先训练的LLM来初始化密集检索器的双编码器。具体而言,GTR 采用 T5 系列模型,包括 T5-base、Large、XL 和 XXL,对密集猎犬进行初始化和微调。RepLLaMA 在IR的多个阶段(包括检索和重新排序)上进一步微调了LLaMA模型。对于密集检索任务,RepLLaMA 附加序列末尾标记” < /秒 > “到输入序列,即查询或文档,并将其视为查询或文档的表示。实验再次证实,更大的模型尺寸可以带来更好的性能,尤其是在零样本设置下。值得注意的是,RepLLaMA 的研究人员还研究了在重新排名阶段应用 LLaMA 的有效性,这将在第 5.1.3 节中介绍。
任务感知检索器。虽然上述研究主要集中在使用 LLM 作为下游检索任务的文本嵌入模型,但当集成特定于任务的指令时,检索性能可以大大提高。例如,TART 设计了一个任务感知检索模型,该模型在问题之前引入了特定于任务的指令。此指令包括对任务意图、域和所需检索单元的描述。例如,鉴于任务是问答,有效的提示可能是“检索此问题的维基百科文本。{问题}“。在这里,“Wikipedia”(域)表示检索到的文档的预期来源,“text”(单位)表示要检索的内容类型,“answer this question”(intent)表示检索到的文本与问题之间的预期关系。这种方法可以利用强大的语言建模能力和 LLM 的广泛知识来精确捕获用户在各种检索任务中的搜索意图。考虑到检索器的效率,它首先使用交叉编码器架构微调了 TART 完整模型,该模型是从 LLM(例如 T0-3B、Flan-T5)初始化的。然后,通过从 TART-full 中提炼知识来学习从 Contriever 初始化的 TART-dull 模型。
4.2.2生成检索器
传统的 IR 系统通常遵循“索引-检索-排名”范式,根据用户查询来定位相关文档,这在实践中已被证明是有效的。但是,这些系统通常由三个独立的模块组成:索引模块、检索模块和重新排序模块。因此,共同优化这些模块可能具有挑战性,可能会导致次优检索结果。此外,此范例需要额外的空间来存储预构建的索引,从而进一步增加存储资源的负担。最近,基于模型的生成检索方法已经出现,以应对这些挑战。这些方法摒弃了传统的“索引-检索-排名”范式,而是使用统一的模型直接生成与查询相关的文档标识符(即 DocID)。在这些基于模型的生成检索方法中,文档语料库的知识存储在模型参数中,从而消除了索引的额外存储空间。现有的方法已经探索了通过微调和提示LLM来生成文档标识符
微调 LLM。鉴于 LLM 中包含的大量世界知识,利用它们来构建基于模型的生成检索器是很直观的。DSI 是一种在检索数据集上微调预训练的 T5 模型的典型方法。该方法涉及对查询进行编码,并直接对文档标识符进行解码以执行检索。他们探索了多种生成文档标识符的技术,并发现构建语义结构标识符会产生最佳结果。在此策略中,DSI 根据文档的语义嵌入将分层聚类应用于分组文档,并根据文档的分层组为每个文档分配语义 DocID。为了确保输出的 DocID 有效并代表语料库中的实际文档,DSI 使用所有 DocID 构造了一个 trie,并在解码过程中使用约束波束搜索。此外,这种方法观察到,缩放定律表明较大的 LM 会导致性能提高,也适用于生成检索器。
提示 LLM。除了微调LLM进行检索外,人们还发现LLM(例如GPT系列模型)可以通过一些上下文演示直接生成相关的Web URL,供用户查询。LLM 的这种独特能力被认为源于他们对各种 HTML 资源的培训接触。因此,LLM 可以自然地充当生成式检索器,直接生成文档标识符以检索相关文档以进行输入查询。为了实现这一点,提出了一个LLM-URL 模型。它利用 GPT-3 text-davinci-003 模型来生成候选 URL。此外,它还设计了正则表达式,从这些候选文件中提取有效的 URL,以找到检索到的文档。
4.3局限性
尽管已经为LLM增强检索做出了一些努力,但仍有许多领域需要更详细的调查。例如,对检索器的一个关键要求是快速响应,而现有 LLM 的主要问题是庞大的模型参数和过长的推理时间。解决 LLM 的这一限制以确保检索器的响应时间是一项关键任务。此外,即使使用 LLM 来增强数据集(推理时间要求较低的上下文),LLM 生成的文本与实际用户查询之间的潜在不匹配也可能影响检索效率。此外,由于 LLM 通常缺乏特定领域的知识,因此在将它们应用于下游任务之前,需要对特定于任务的数据集进行微调。因此,开发有效的策略来微调这些具有众多参数的 LLM 成为一个关键问题。
5Reranker
Reranker 作为 IR 中的第二遍文档过滤器,旨在根据查询文档相关性对检索器检索到的文档列表(例如 BM25)进行重新排序。基于LLM的使用,现有的基于LLM的重排序方法可以分为三种范式:利用LLM作为监督重排序器,利用LLM作为无监督重排序器,以及利用LLM进行训练数据增强。表五总结了这些范式,并将在以下各节中详细阐述。回想一下,我们将使用术语“文档”来指代在一般 IR 场景中检索到的文本,包括段落等实例(例如,MS MARCO 段落排名数据集 中的段落)。
5.1利用 LLM 作为受监督的重新排序器
监督微调是将预训练的 LLM 应用于重新排序任务的重要步骤。由于在预训练中缺乏排名意识,LLM 无法正确衡量查询文档的相关性,也无法充分理解重新排名任务。通过对特定于任务的排名数据集(例如MS MARCO段落排名数据集)上的LLM进行微调,该数据集包括相关和不相关的信号,LLM可以调整其参数,以在重新排名任务中产生更好的性能。根据主干模型结构,我们可以将现有的监督重排序器分类为:(1)仅编码器,(2)编码器-解码器和(3)仅解码器。
5.1.1仅编码器
基于编码器的重新排序器代表了将 LLM 应用于文档排名任务的一个重要转折点。他们展示了如何对一些预训练的语言模型(例如BERT )进行微调,以提供高度准确的相关性预测。一种具有代表性的方法是monoBERT ,它将查询-文档对转换为序列“ query document ”作为模型输入,并通过将“”表示馈送到线性层中来计算相关性分数。重新排序模型基于交叉熵损失进行优化。
5.1.2编码器-解码器
在该领域,现有研究主要将文档排序表述为生成任务,并优化基于编码器-解码器的重新排序模型。具体来说,给定查询和文档,通常会对模型进行微调以生成单个标记,例如“true”或“false”。在推理过程中,查询文档相关性分数是根据生成的令牌的 logit 确定的。例如,可以对T5模型进行微调,为相关或不相关的查询-文档对生成分类标记。在推理时,softmax 函数应用于 “true” 和 “false” 标记的对数,并将相关性分数计算为“true”标记的概率。以下方法涉及基于T5模型的多视图学习方法。此方法同时考虑两个任务:为给定的查询-文档对生成分类标记,并生成以提供的文档为条件的相应查询。DuoT5 考虑三重 ( , 我 , ) 作为 T5 模型的输入,并经过微调以生成令牌“true”if 文档 我 与查询更相关 我 比文档 ,否则为“false”。在推理过程中,对于每个文档 我 ,它枚举了所有其他文档 并使用全局聚合函数生成相关性分数 我 对于文档 我 (例如, 我 = ∑ 我 , 哪里 我 , 表示在采取 ( , 我 , ) 作为模型输入)。
尽管这些基于生成损失的方法优于几个强大的排名基线,但它们并不是重新排名任务的最佳选择。这主要有两个原因。首先,通常预期重新排序模型将为每个查询-文档对(而不是文本标记)生成数字相关性分数。其次,与生成损失相比,使用排名损失(例如,RankNet )优化重新排名模型更为合理。最近,RankT5 直接计算了查询-文档对的相关性得分,并通过“成对”或“列表”的排名损失优化了排名性能。潜在性能增强的途径在于用更大规模的对应物替换基本尺寸的 T5 模型。
5.1.3仅解码器
最近,有一些尝试通过微调仅解码器模型(如LLaMA)来重新排列文档。例如,RankLLaMA 建议将查询-文档对格式化为提示“query: {query} document: {document} ”,并利用最后一个标记表示进行相关性计算。此外,还提出了RankingGPT,通过两阶段训练来弥合LLM的常规训练目标与文档排名的特定需求之间的差距。第一阶段涉及使用从 Web 资源收集的大量相关文本对持续预训练 LLM,帮助 LLM 自然地生成与输入文档相关的查询。第二阶段的重点是使用高质量的监督数据和精心设计的损失函数来提高模型的文本排名性能。与这些逐点重新排名器不同,Rank-without-GPT 建议训练一个列表式重新排名器,该重新排名器直接输出重新排名的文档列表。作者首先证明,现有的逐点数据集(如MS MARCO )仅包含二进制查询文档标签,不足以训练有效的列表重排序器。然后,他们建议使用现有排名系统(如 Cohere rerank API)的排名结果作为黄金排名,以训练基于 Code-LLaMA-Intit 的列表式重新排名器。
 Figure 6:Three types of unsupervised reranking methods: (a) pointwise methods that consist of relevance generation (upper) and query generation (lower), (b) listwise methods, and (c) pairwise methods.
Figure 6:Three types of unsupervised reranking methods: (a) pointwise methods that consist of relevance generation (upper) and query generation (lower), (b) listwise methods, and (c) pairwise methods.5.2利用 LLM 作为无监督的重新排序器
随着 LLM 的规模扩大(例如,超过 100 亿个参数),微调重新排名模型变得越来越困难。为了应对这一挑战,最近的努力试图促使 LLM 以无监督的方式直接增强文档重新排名。通常,这些提示策略可以分为三类:逐点方法、列表方法和成对方法。后续各节将全面探讨这些策略。
5.2.1逐点方法
逐点方法测量查询与单个文档之间的相关性,可分为两种类型:相关性生成和查询生成。
图 6 (a) 中的上半部分显示了基于给定提示生成相关性的示例,其中 LLM 根据文档是否与查询相关输出二进制标签(“Yes”或“No”)。在 之后,查询文档相关性得分 ( , ) 可以使用 softmax 函数根据令牌 “Yes” 和 “No” 的对数似然计算:
哪里 和 分别表示 LLM 的对数似然得分“是”和“否”。除了二元标签之外,Zhuang等还建议将细粒度的相关性标签(例如,“高度相关”、“有点相关”和“不相关”)纳入提示中,这有助于LLM更有效地区分与查询具有不同相关性的文档。
对于图 6 (a) 下半部分所示的查询生成,查询文档相关性得分由基于文档生成实际查询令牌的平均对数似然决定:
哪里 | | 表示查询的令牌号 , 表示文档,并且 表示提供的提示。然后,根据文档的相关性分数对文档进行重新排名。已经证明,一些LLM(如T0)在基于查询生成方法的零样本文档重新排序中产生了显著的性能。最近,研究还表明,在没有任何监督指令微调的情况下进行预训练的LLM(如LLaMA)也产生了强大的零样本排名能力。
虽然有效,但这些方法主要依赖于手工制作的提示(例如,“请根据本文档编写查询”),这可能不是最佳选择。由于提示是指示 LLM 执行各种 NLP 任务的关键因素,因此优化提示以获得更好的性能非常重要。沿着这条思路,提出了一种离散提示优化方法Co-Prompt,以便在重新排序任务中更好地生成提示。此外,PaRaDe提出了一种基于难度的方法,选择少量的演示包含在提示中,与零镜头提示相比,有显著的改进。
请注意,这些逐点方法依赖于访问 LLM 的输出日志来计算查询文档相关性分数。因此,它们不适用于闭源 LLM,其 API 返回的结果不包括 logit。
TABLE VI:The comparison between different methods. denotes the number of documents to rerank. The Complexity, Logits, and Batch represent the computational complexity, whether accesses LLM’s logits, and whether allows batch inference respectively. is the constant in sliding windows strategy. As for the Performance, we use NDCG@10 as a metric, and the results are calculated by reranking the top 100 documents retrieved by BM25 on TREC-DL2019 and TREC-DL2020. The best model is in bold while the second-best is marked with an underline. The results come from previous study . *Since the parameters of ChatGPT have not been released, its model parameters are based on public estimates .
方法 | LLM | 大小 | 性能 | 性能 | ||||
复杂性 | 日志 | 配料 | TREC-DL19 | TREC-DL20 | ||||
初始猎犬 | BM25 | - | - | - | - | - | 50.58 | 47.96 |
监督 | monoBERT | BERT | 340M | - | 定义 | 定义 |
发布于 2025-09-06 20:11
1
推荐阅读 | |